

Cluster Operation#
Allegra can be operated in a clustered environment, i.e., an Allegra instance can run on multiple servers. This section provides examples of possible configurations and explains how Allegra behaves in a clustered environment.
Cluster Configurations#
For web applications, there are two types of clusters: High Availability clusters (HA) and Load Balancing clusters.
With a High Availability cluster, you can improve the availability of the Allegra service to ensure, for example, 24/7 operation. An HA cluster works with redundant nodes that are used to provide services in the event of system component failures. The most common size for an HA cluster is two nodes, which represents the minimum requirement for redundancy. By using redundancy, HA cluster implementations eliminate single points of failure.
The figure below shows a simple HA cluster with two application servers and one database server. The database server is not redundant, but it would be possible to use one of the application servers as a redundant database server. The router that switches between application server 1 and application server 2 is not shown here.
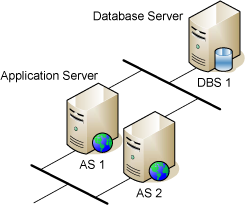
The purpose of a Load Balancing cluster is to distribute a workload evenly across multiple backend nodes. Typically, the cluster is configured with multiple redundant load balancing frontends. Since every element in a Load Balancing cluster must provide full service, you can think of it like an active/HA cluster where all available servers process requests.
The following figure shows a fairly large configuration with a load balancer, five application servers, two database servers, and two file servers.
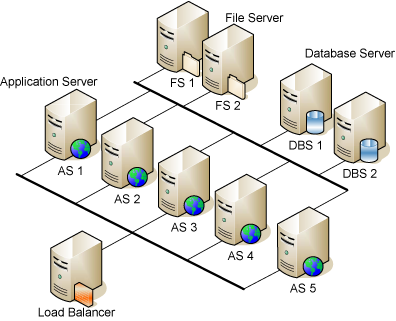
All application servers work with a single database, which is redundantly served by two database servers. The attachments and full-text search indexes are kept on a single file server, which also has a backup. The backup of the file server is left to the operating system, Allegra does not provide support for this.
The database management system must take care of the synchronization between the original database server and the backup database server.
All communication between the different Allegra application servers of a cluster is handled via the database. There is no need to open special ports for communication between the application servers or to use patched virtual Java machines.
Note
No configuration is required in Allegra for operation in a cluster environment. If you connect multiple Allegra instances to the same database, Allegra automatically switches to cluster operating mode. However, you will need a corresponding license key that includes all application servers you connect to this database.
Many other configurations are possible. For example, one of the application servers can also be the file server. Or the database server and the file server can be installed on the same hardware. Allegra itself does not care about all this, as long as you ensure that you have exactly one access point (JDBC URL) for the database and exactly one file path to the attachment and index directories for all Allegra instances of this cluster.
Startup Behavior#
When an Allegra instance is started, it registers itself as a node in the database.
Then the database is searched for other nodes. If there are nodes in the database that
have not updated their entry within a certain timeout period (default is 5 minutes, can be set in the file
WEB-INF/quartz-jobs.xml), this entry is deleted from
the table.
After that, Allegra tries to set itself as the master node, unless there is already another node marked as the master node. If this is the only node, the operation is immediately successful. Otherwise, it can take up to the timeout period for a new master node to be fully set up.
The master node is responsible for
updating the full-text search index
retrieving emails from an email server if article delivery via email is enabled.
Otherwise, the master node behaves like a normal node.
Master Node Fails#
If the master node fails, the full-text search is temporarily not updated. However, no activities are lost that require an update of the full-text search index as they are stored in the database.
Also, the retrieval of emails from the email server is temporarily disabled. Again, no inputs are lost as they are stored on the email server.
After a maximum of one timeout period (default value is 5 minutes, set in
WEB-INF/quartz-jobs.xml), the remaining nodes begin negotiating
who will replace the original master node. The result is random. The new
master node begins updating the full-text search index and
retrieving emails from the email server.
So, the failure of a master node results in slightly reduced performance and a delay of about 5 minutes in updating the full-text search index.
Failure of a Regular Node#
If a regular node fails, there is some drop in performance.
The other nodes take less than the timeout period (default is 5 minutes,
set in WEB-INF/quartz-jobs.xml) to recognize that a node has failed
but this has no further consequences.
Forced Change of Master Node#
Normally, all application nodes negotiate among themselves who should become the master node. The result is random.
However, it is possible to force one of the nodes to become the master node. For this, the current master node must be instructed to stop its master node related operations, such as updating the full-text search index, and make way for the new master node. This process can take up to the timeout period (default is 5 minutes) before the new node can assume its responsibility as the new master node.